Apple hat acht kleine Prototypen von KI-Sprachen veröffentlicht, die für die Verwendung auf dem Gerät vorgesehen sind

Getty Images
In der Welt der künstlichen Intelligenz erfreuen sich sogenannte „Mikrosprachmodelle“ in letzter Zeit zunehmender Beliebtheit, da sie auf einem lokalen Computer ausgeführt werden können, ohne Computer auf Rechenzentrumsebene in der Cloud zu benötigen. Apple Mittwoch Fuß Eine Reihe kleiner, öffentlich verfügbarer KI-Sprachmodelle namens OpenELM, die klein genug sind, um direkt auf einem Smartphone ausgeführt zu werden. Im Moment handelt es sich meist um Proof-of-Concept-Forschungsmodelle, sie könnten aber die Grundlage für zukünftige On-Device-KI-Angebote von Apple bilden.
Die neuen KI-Modelle von Apple, gemeinsam OpenELM (Open Source Efficient Language Models) genannt, sind derzeit unter verfügbar Gesichtsumarmung unter Beispiellizenz für Apple-Code. Aufgrund einiger Einschränkungen in der Lizenz ist es möglicherweise nicht kompatibel mit Allgemein akzeptierte Definition „Open Source“, aber der Quellcode für OpenELM ist verfügbar.
Am Dienstag haben wir über die Phi-3-Modelle von Microsoft berichtet, die etwas Ähnliches erreichen wollen: ein nützliches Maß an Sprachverständnis und Verarbeitungsleistung in kleinen KI-Modellen, die lokal ausgeführt werden können. Der Phi-3-mini verfügt über 3,8 Milliarden Parameter, aber einige der OpenELM-Modelle von Apple sind viel kleiner und reichen von 270 Millionen bis 3 Milliarden Parametern in acht verschiedenen Modellen.
Im Vergleich dazu umfasst das größte bisher veröffentlichte Modell der Llama-3-Familie von Meta 70 Milliarden Parameter (eine Veröffentlichung mit 400 Milliarden ist geplant), und GPT-3 von OpenAI aus dem Jahr 2020 wird mit 175 Milliarden Parametern ausgeliefert. Die Anzahl der Parameter ist ein grobes Maß für die Leistungsfähigkeit und Komplexität eines KI-Modells. Die jüngste Forschung hat sich jedoch darauf konzentriert, kleinere KI-Sprachmodelle genauso leistungsfähig zu machen wie die größeren, die sie vor einigen Jahren hatten.
Die acht OpenELM-Modelle gibt es in zwei Versionen: vier als „vorab trainiert“ (im Wesentlichen eine frühe Version des nächsten Modells) und vier als anweisungsoptimiert (fein abgestimmt, um Anweisungen zu befolgen, idealer für die Entwicklung von KI-Assistenten und Chatbots):
OpenELM verfügt über ein Kontextfenster mit maximal 2048 Token. Die Modelle wurden anhand öffentlich verfügbarer Datensätze trainiert RefinedWebEine Kopie von Haufen Nachdem Duplikate entfernt wurden, entsteht eine Teilmenge von Roter Pyjamaund eine Teilmenge von Dolma v1.6, was laut Apple etwa 1,8 Billionen Daten-Tokens umfasst. Token sind segmentierte Darstellungen von Daten, die KI-Sprachmodelle zur Verarbeitung verwenden.
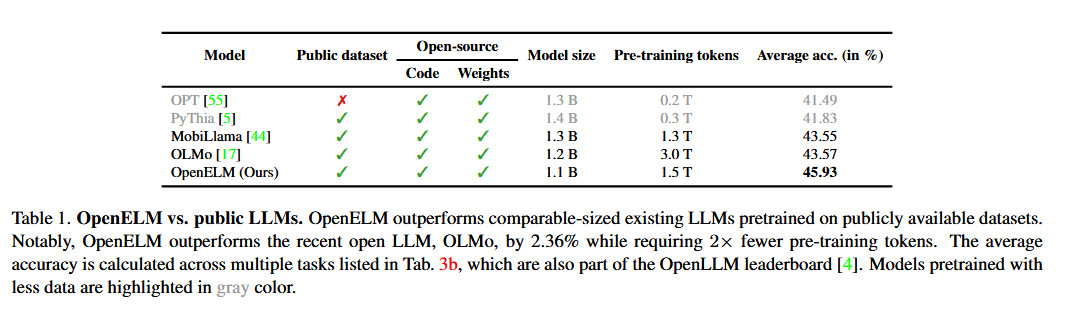
Apple sagt, dass sein Ansatz mit OpenELM eine „Layer-Skalierungsstrategie“ beinhaltet, die Parameter effizienter über jede Ebene verteilen soll, was nicht nur Rechenressourcen spart, sondern auch die Leistung des Modells verbessert, da es mit weniger Token trainiert. Laut den Angaben von Apple weiße PapiereDurch diese Strategie konnte OpenELM eine Genauigkeitsverbesserung von 2,36 Prozent im Vergleich zu allen KI-Systemen erzielen Olmo 1b (ein weiteres kleines Sprachmodell), erfordert aber die Hälfte der Token für das Vortraining.
Apfel
Apple hat auch den Code für veröffentlicht Kernnetz, eine Bibliothek, die ich zum Trainieren von OpenELM verwendet habe, enthielt auch wiederholbare Trainingsrezepte, die sich wiederholende Gewichtungen (neuronale Netzwerkdateien) ermöglichen, was für ein großes Technologieunternehmen bisher ungewöhnlich ist. Wie Apple in seiner OpenELM-Forschungszusammenfassung sagt, ist Transparenz ein zentrales Ziel des Unternehmens: „Die Reproduzierbarkeit und Transparenz großer Sprachmodelle ist entscheidend für die Förderung offener Forschung, die Gewährleistung der Zuverlässigkeit der Ergebnisse und die Ermöglichung von Untersuchungen zu Daten- und Modellverzerrungen.“ sowie potenzielle Risiken.“
Durch die Veröffentlichung des Quellcodes, der Modellgewichte und der Schulungsmaterialien will Apple laut eigenen Angaben „die offene Forschungsgemeinschaft stärken und bereichern“. Allerdings wird auch darauf hingewiesen, dass, da die Modelle auf öffentlich zugänglichen Datensätzen trainiert werden, „die Möglichkeit besteht, dass diese Modelle als Reaktion auf Benutzeraufforderungen ungenaue, schädliche, voreingenommene oder anstößige Ergebnisse liefern.“
Obwohl Apple diese neue Welle von KI-Sprachmodellfunktionen noch nicht in seine Verbrauchergeräte integriert hat, soll das kommende iOS 18-Update (voraussichtlich im Juni auf der WWDC vorgestellt) neue KI-Funktionen enthalten, die die Verarbeitung unterwegs nutzen. Gerät zur Gewährleistung des Benutzers. Datenschutz – Obwohl es wahrscheinlich ist, dass das Unternehmen Google oder OpenAI damit beauftragen wird, die komplexere KI-Verarbeitung außerhalb des Geräts zu übernehmen, um Siri einen längst überfälligen Schub zu geben.

„Bier-Geek. Der böse Ninja der Popkultur. Kaffee-Stipendiat fürs Leben. Professioneller Internet-Lehrer. Fleisch-Lehrer.“


/cloudfront-us-east-2.images.arcpublishing.com/reuters/C3QGH34SWFJJPO6IWG3DJKHPT4.jpg "Lokale Medien berichteten, dass Apple-Mitbegründer Wozniak in Mexiko einen möglichen Schlaganfall erlitten habe")

